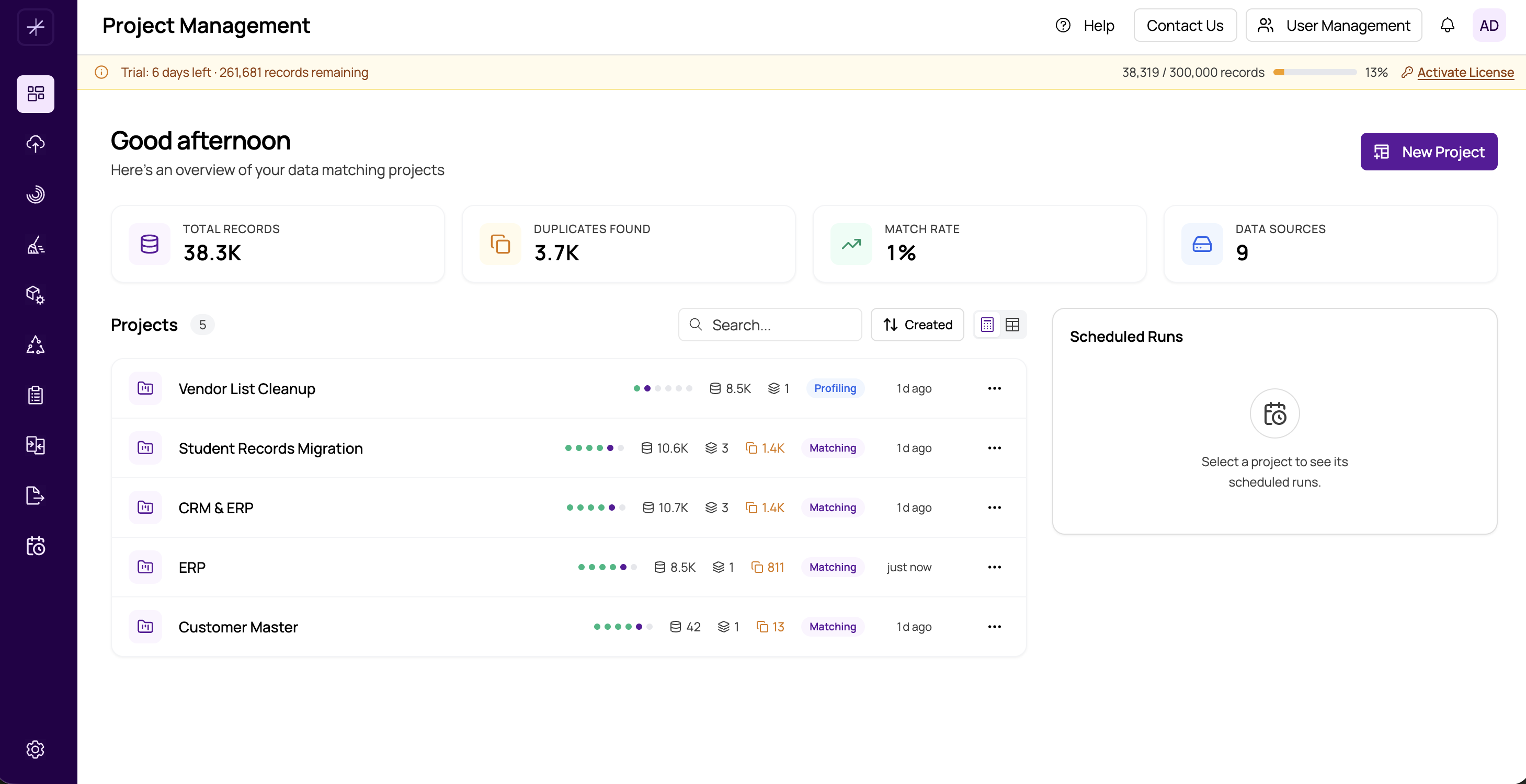
What Is MatchLogic?
MatchLogic is a data matching and quality platform that helps organizations find duplicate records, link related data across multiple sources, and produce a single clean, trusted dataset. Whether you are deduplicating a customer list, reconciling records between a CRM and an ERP system, or preparing data for migration, MatchLogic provides the tools to get it done without writing code.
What Does MatchLogic Do?
At its core, MatchLogic takes your raw data and guides it through a structured pipeline that ends with a clean, deduplicated, and merged output. The platform handles every stage of the process:
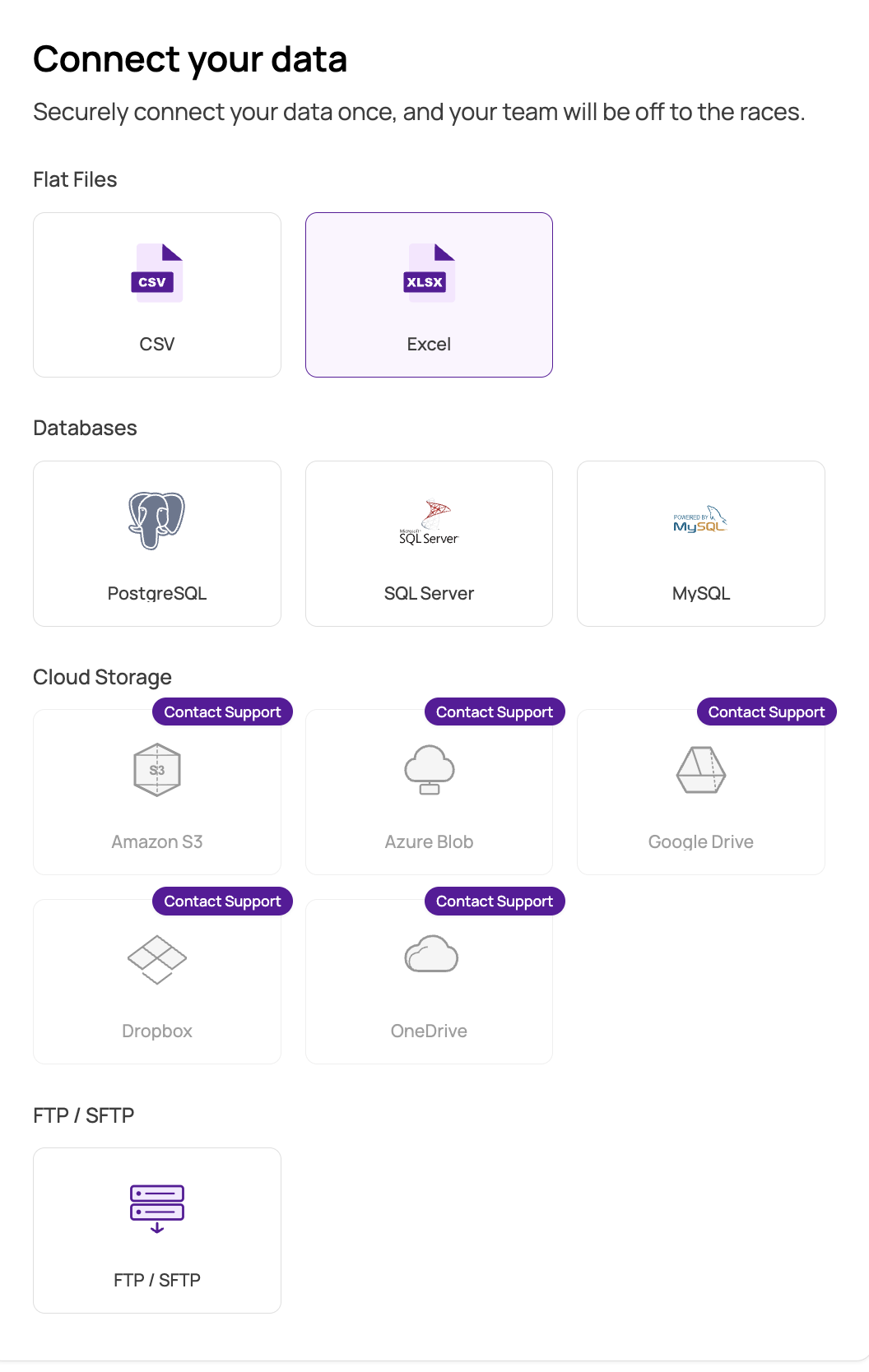
- Import data from files, databases, or cloud storage services.
- Profile data quality to understand completeness, consistency, patterns, and anomalies before matching.
- Cleanse and standardize data using a visual rule builder so that records are comparable.
- Configure matching strategies to control which datasets are compared and how.
- Define match rules that specify which fields to compare, what comparison methods to use, and how to weight each field.
- Review match results with interactive pair and group views, confidence scores, and summary reports.
- Merge records by setting master-record rules and field-level survivorship logic.
- Export the final output to a file, database, or cloud destination.
Who Is It For?
MatchLogic is designed for data teams, business analysts, data stewards, and operations professionals who need to improve data quality without relying on engineering resources. If your work involves any of the following, MatchLogic can help:
- Cleaning up duplicate customer, patient, or vendor records.
- Linking records across systems that share no common identifier.
- Preparing data for a migration, consolidation, or reporting initiative.
- Ongoing data quality monitoring and remediation.
Key Advantages
- Visual, no-code pipeline. Every step is accessible through a guided interface. You configure matching rules, cleansing logic, and survivorship strategies by selecting options rather than writing scripts.
- Flexible data connectivity. Import from CSV files, Excel spreadsheets, PostgreSQL, MySQL, SQL Server, Amazon S3, Azure Blob Storage, FTP/SFTP, Google Drive, Dropbox, and OneDrive. Export to the same destinations plus Neo4j for graph-based analysis.
- Multiple matching methods. Combine exact matching, fuzzy string comparison, phonetic encoding, and numeric matching within a single project. Assign weights to each field so the overall score reflects your business priorities.
- Interactive result review. Inspect matched pairs and groups with confidence scores, drill into individual records, and override automated decisions where needed.
- Deterministic survivorship. Define clear rules for which record wins and which field values survive into the final merged output, ensuring repeatable and auditable results.

Tip
New to MatchLogic? Start with the quick-start-first-dedup-project tutorial to walk through a complete deduplication project in under 15 minutes.
How It Works at a High Level
Every MatchLogic project follows a sequential pipeline of nine modules. You begin by creating a project, importing one or more datasets, and optionally profiling and cleansing the data. Next, you configure which datasets to compare and define the rules that determine whether two records match. After running the match, you review and refine the results, set merge and survivorship rules, and export the final clean dataset.
Each module builds on the output of the previous one, and the platform tracks your progress so you can return to any step at any time. Once matching is complete, the Match Results screen gives you a full quality report — including total record pairs found, match rate, score distribution, and a breakdown by data source and match definition.

For a detailed walkthrough of every stage, see https://help.matchlogic.io/article/196-the-data-matching-pipeline.